
If you ever worked with Palo Alto DAG (Dynamic Address Groups), you have an idea of how powerful it can be.
If you ever worked with Palo Alto DAG, you also have an idea of how unscalable it is (for now).
Using it in production (mixed with static groups, which are the most commonly used yet), we noticed that devices using DAG take a lo[oooooooooo]t more time to commit changes than others (up to 45 minutes for some). Based on Palo Alto TAC support, it’s because of the matching logic, which is performed at commit time, and populates groups which becomes static based on the DAG condition string and objects tags : “Flattening the config to use static address group is the only option as DAGs involve TAG table construction and evaluation of DAGs for every IP”
On my side, I worked on a Palo Alto policy / objects cleaning tool (available here), on which I had a similar problematic. Processing the DAG matching logic was taking a lot of time and was very resource consuming, up to the time I decided to review the logic behind, which finally allowed me to drastically improve its efficiency. Let’s review it together.
Reminders about DAGs
For those who are not familiar with it, let’s review the principle behind DAG (Dynamic Address Groups).
There are several ways to group address objects (IP hosts / ranges or FQDN) into “groups” which can then be used on the policy.
The most used ones are static-groups, on which members can be statically added, as their name says :

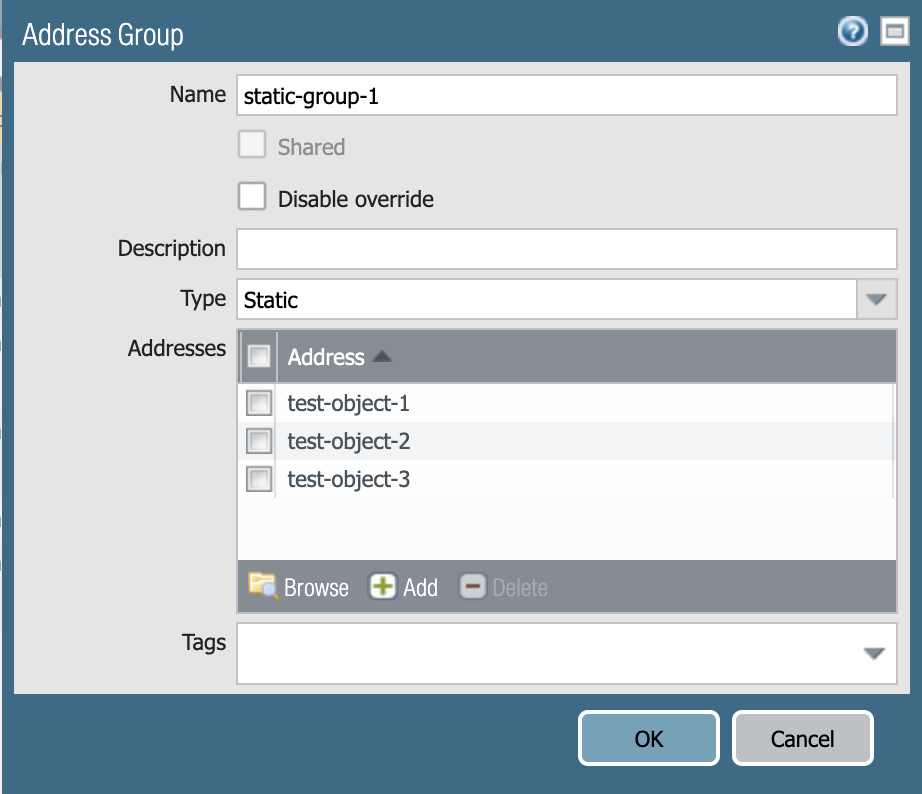
Among other specificities, if you use it on Panorama with device-groups logic (hierarchy), those ones can include objects existing at the same level than the group itself and above.
The ones which interest us in this article are a bit different : DAG (Dynamic Address Groups) are matching members objects dynamically, by using their tags.
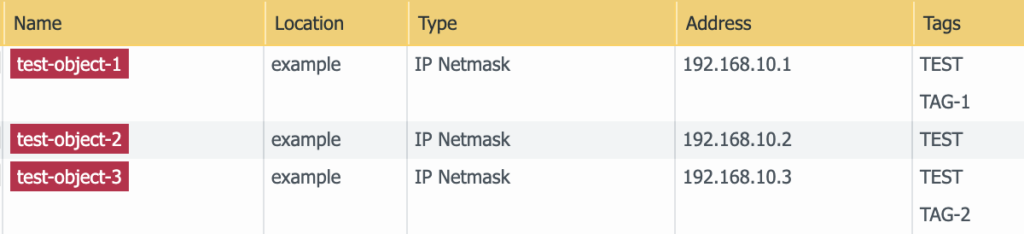
As you probably now, each address and group object can be assigned tags.
Let’s add some to our objects :
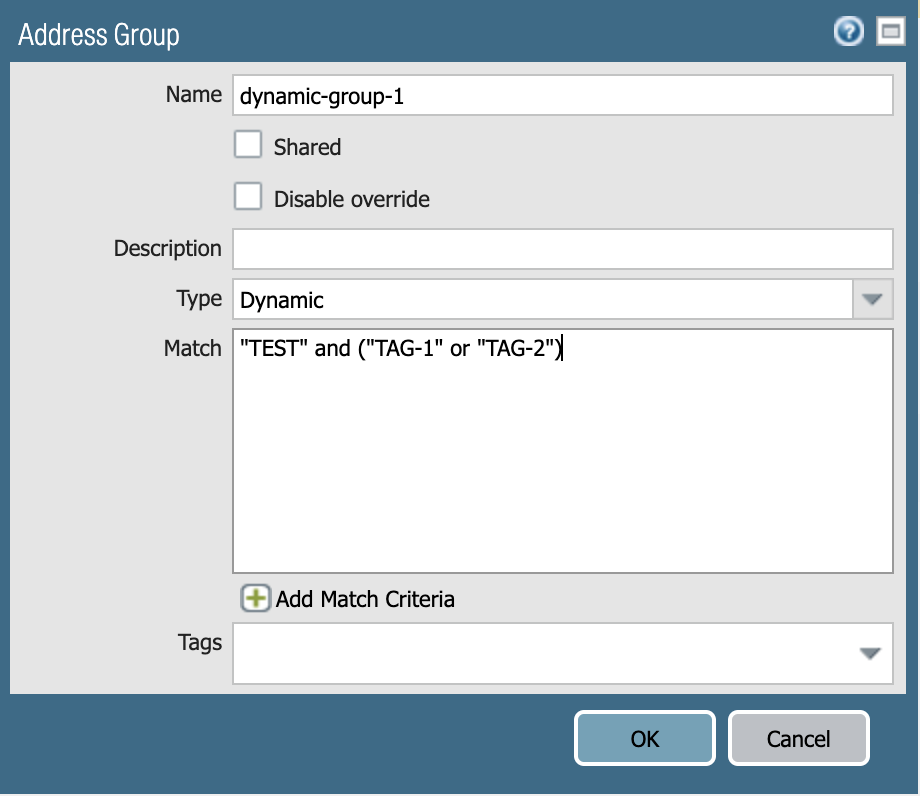
Now if we create a dynamic address group, we can configure it with a string condition, which defines which objects should be member of the DAG. The dynamic group below will match all objects having the “TEST” tag, and either “TAG-1” or “TAG-2” (or both) :
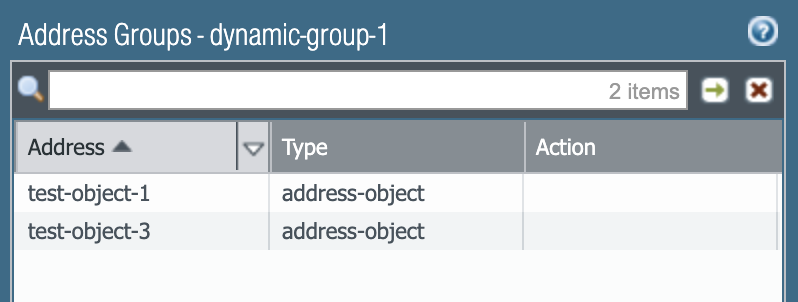
By clicking the “more…” link in the dynamic groups list, we can see matched objects :

Again, among other specificities, those groups permit to match any object matching the condition string at any location, from the one where it is used, up to the “shared” objects existing at Panorama level.
Because of it, Panorama does not performs the membership processing, but offloads this calculation to all firewall appliances, as the DAG could match objects existing only locally on the appliance, not known to Panorama.
Each time a commit is performed on the firewall (either locally or from Panorama), the calculation of the condition string matches needs to be performed, to resolve the list of matching objects and populate a data structure which becomes static (DAG are not, of course, processed each time a flow matches a rule where a DAG is used).
But let’s talk about the specific use case I had to work on, and we’ll further discuss about the logic used by the Palo appliances later.
How to match DAG members in Python : the iterative method
As explained in the introduction of this article, I worked on a cleaning tool, which the role is to remove any unused object / replace any duplicate object on all policies configured on Panorama.
For this purpose, of course, this script needs to be able to perform this same calculation : resolving all objects that matches the DAG condition string at the level where they are used, to make sure it will not delete any used object (the difference between static and dynamic groups is that Panorama or the firewall itself will not warn you if you are deleting an object matched by a DAG, while it will block you if you try to delete an object statically referenced on a static group).
I will here explain how I initially developed this logic, and why it is clearly not the good way to proceed and how I improved it.
(BTW : as a contributor for this project, I use the Palo Alto pan-os-python SDK to interact with Panorama and firewall appliances, and I’ll use it here also to work with AddressObjects and AddressGroup instances).
Part 1 : let’s build a significant amount of random objects
In order to measure the performance of the matching logic, we need to generate a significant amount of objects (each having assigned a random set of tags from a pool), which we’ll use on DAG condition strings.
from panos.objects import AddressObject, Tag
import random
import uuid
# generate a list of x tags (here, 6), in the form of TAG-0, TAG-1, TAG-2...
tag_list = [Tag(name='TAG-' + str(x)) for x in range(6)]
# function which creates objects with a random IP address value and a random amount of tags from the tag_list. The name of each object is a UUID v4 value.
def generate_random_object():
# generate a random IP address
ip_addr = ".".join([str(random.randint(1, 255)) for _ in range(4)])
# generate a name in the form of an UUID v4
name = str(uuid.uuid4())
# add between 0 and 5 tags from the tag_list pool
tags = set()
for _ in range(random.randint(0,5)):
tags.add(str(tag_list[random.randint(0, len(tag_list) - 1)]))
return AddressObject(name=name, value=ip_addr, tag=list(tags))
# let's generate 200k objects and put in on a list
address_objects = [generate_random_object() for _ in range(200000)]By using a simple “print_object()” method, here’s a view of a dozen of those randomly generated objects :
def print_object(obj):
print(f"{obj.name} - {obj.value} - {obj.tag}")
any(print_object(address_objects[x]) for x in range(12))Result :
7c433773-7c93-43a5-8614-e43a11e62b72 - 90.246.42.244 - ['TAG-0', 'TAG-2', 'TAG-1']
f2aa3035-2474-4fa2-b595-bcd0890cf27b - 216.113.101.96 - ['TAG-4', 'TAG-5']
aa10d48a-1293-49e9-83e5-1a91def0cfb7 - 177.100.207.180 - ['TAG-5', 'TAG-0', 'TAG-3']
6e015264-13f4-40d8-99e8-2e15488aa879 - 97.113.90.38 - ['TAG-4', 'TAG-5', 'TAG-3']
152d9961-ccc6-4eb7-947b-388ef0954636 - 154.215.243.41 - ['TAG-5', 'TAG-2', 'TAG-3']
4ef65ee2-f651-45cf-a0fb-221b8db45450 - 35.27.129.210 - []
282f27ac-76a7-49f2-a485-1da0954333e2 - 104.39.246.157 - ['TAG-0', 'TAG-2', 'TAG-3']
044aa265-88fb-4a12-b61f-f7d1b4c35979 - 52.204.73.51 - ['TAG-5', 'TAG-0', 'TAG-3']
8c273359-ff23-4a28-af1b-8314444a16d2 - 55.30.137.8 - ['TAG-1']
0f6b926c-a6db-4474-9ff9-be8f01e9bd8c - 36.206.219.128 - ['TAG-0']
2f7e99ec-d77c-4736-ac98-0136026d4ef4 - 148.9.187.248 - ['TAG-0', 'TAG-1']
fa5d7e12-c882-41f0-a167-869f9e6c5c70 - 57.208.158.240 - ['TAG-5', 'TAG-0', 'TAG-2']Part 2 : create the DAG condition string matching function
To check which objects matches a given DAG condition string, let’s create a function which will take this condition string as an input, transform it as an executable Python statement, and will iterate over the address_objects list to test each object on it.
For this specific demo, the function will only return the number of matched objects.
def find_with_list_iteration(condition_expression):
# changes a DAG condition expression into an executable Python statement
# checking presence of the tags into the obj.tag list
# ie : ('TAG-1' and 'TAG-2') or 'TAG-3' becomes
# cond_expr_result = ('TAG-1' in obj.tag and 'TAG-2' in obj.tag) or 'TAG-3' in obj.tag
exec_statement = "cond_expr_result = " + re.sub("'((\w|[-:\+])+)'", rf"'\1' in obj.tag", condition_expression)
print(f"Python statement is : {exec_statement}")
matched_objects = set()
for obj in address_objects:
exec_result = dict()
# execute our statement, exposing only the 'obj' variable. The result will be get on the exec_result dict
exec(exec_statement, {'obj': obj}, exec_result)
if exec_result.get('cond_expr_result') is True:
# if the result of the statement is True for an object, add it to the matched_objects set
matched_objects.add(obj)
print(f"{len(matched_objects)} found")
return len(matched_objects)Part 3 : let’s try it with manually provided condition strings
To validate the proper working of our function, let’s try it with some manual tests condition strings :
while True:
try:
condition_expression = input("DAG expression : ")
if condition_expression == "exit" or condition_expression == "":
break
print("Start search with iterative lookup")
start_find_iterative = datetime.datetime.now()
find_with_list_iteration(condition_expression)
end_find_iterative = datetime.datetime.now()
print(f"OK Took {end_find_iterative - start_find_iterative}")
except Exception as e:
print(e)
pass>>> DAG expression : 'TAG-1' and ('TAG-2' or 'TAG-3')
Start search with iterative lookup
Python statement is : cond_expr_result = 'TAG-1' in obj.tag and ('TAG-2' in obj.tag or 'TAG-3' in obj.tag)
41464 found
OK Took 0:00:04.444035We can see here that the time needed to find the 41464 matching objects among our 200k list is around 4,4 seconds.
Now let’s imagine that we have 300 DAG on a firewall. The time needed to populate those ones at compile time would be (depending of the condition string complexity) around 300 * 4,4 seconds = 1 320 seconds = 22 minutes.
Improve processing time with sets operations
What are Python sets ?
Sets are a quite useful kind of collection type available in Python. They are actually completely equal to dictionaries (key-value pairs), which are…. hash tables (that’s why they can only be used with hashable objects), that we can reproduce in any other language.
The idea behind a set is that it contains each object one time only (avoiding collisions thanks to the hash value of the object which is used as the key).
Operations can be performed on sets, such as union, intersection, symmetric difference…
The representation of those operations can be found below (source : www.analyticsvidhya.com)
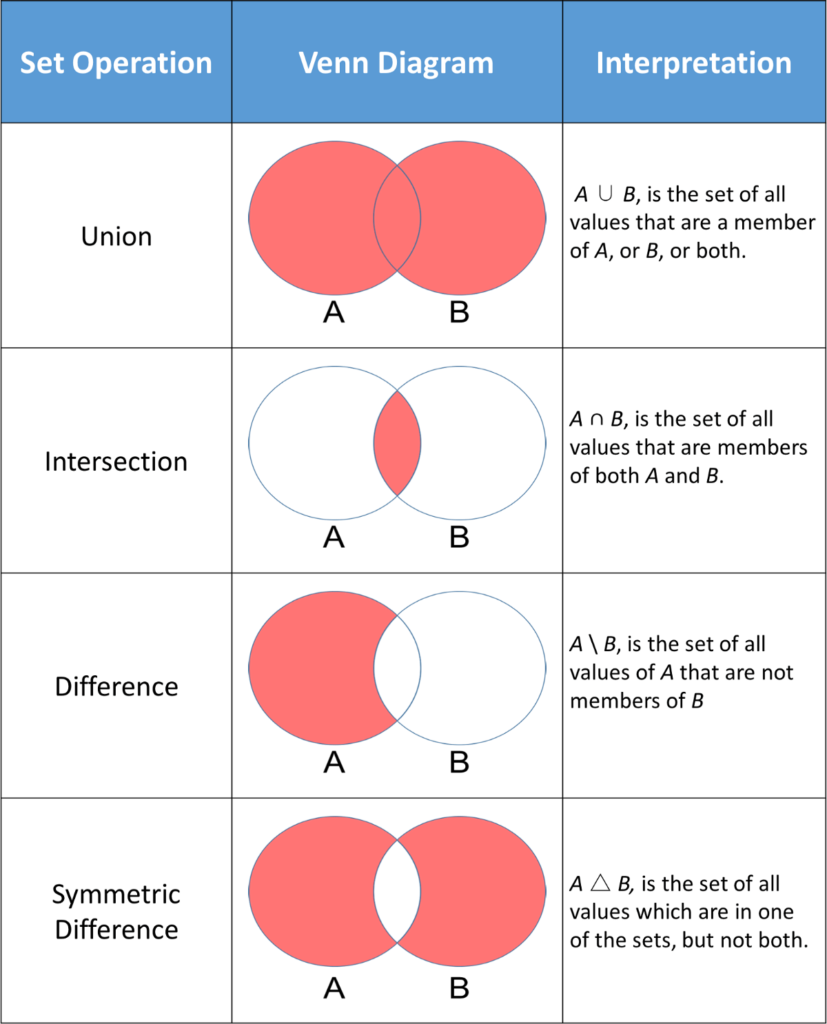
Let’s compare it with our DAG membership logic.
Let’s imagine we have several sets, one per tag we use. Each set contains all objects having the specific tag corresponding to the set.
(IE : comparing with our example from the beginning of this post, we would have this result)
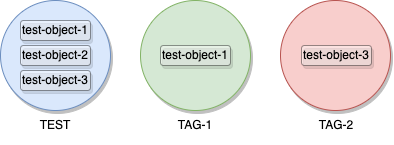
Now, thinking about the sets operations.
If we want to get the list of all objects having tags “TEST” and “TAG-1”, we could just find the intersection between the “TEST” set and the “TAG-1” set.
If we want to get the list of all objects having tags “TAG-1” or “TAG-2” (or both), we could find the union of the “TAG-1” set and the “TAG-2” set.
The advantage using this method :
– sets operations are amazingly fast, because of the fact that they are based on hash tables
– only 1 operation (or composed statement) is needed to find the full list of objects matching a composed set operation. No need to iterate over a list
Part 1 : let’s create our per-tag sets
Using a simple function, we can populate a dict, for which the key will be the tag value for any tag discovered on our random objects, and the value will be a set on which we’ll add the objects having this tag.
We’ll also measure the time needed to build this set.
tags_set = dict()
def populate_tags_set():
start_tags_set_build = datetime.datetime.now()
print("Populating tags set...")
# for each object in our address_objects list
for o in address_objects:
# iterate over each tag existing on the object
for t in o.tag:
# if the current tag does not exists as a key on the tags_set dict, create it
# and initialize the value as an empty set
if t not in tags_sets:
tags_sets[t] = set()
# finally add the current object to the set for the current tag
tags_sets[t].add(o)
end_tags_set_build = datetime.datetime.now()
print(f"OK. Took {end_tags_set_build - start_tags_set_build}")Example running it on our 200k random objects :
Populating tags sets...
OK Took 0:00:00.472381Half a second to populate the different sets for 200k objects, we are on a good average.
Part 2 : create the DAG condition string matching function, with sets operations
Let’s change our matching function, this time using sets operations to find the matching objects.
Again, for the purpose of this demo, this function only returns the number of matched objects.
The “&” operator performs an intersection of sets, while the “|” operator performs an union.
It would also have been possible to use <set1>.union(<set2>) or <set1>.intersection(<set2>)
def find_with_sets(condition_expression):
# changes a DAG condition expression into an executable Python statement
# in the form of a sets intersection / union difference
# ie : ("TAG-1" and "TAG-2") or "TAG-3" becomes
# cond_expr_result = (tags_sets.get('TAG-1', set()) & tags_sets.get('TAG2', set())) ^ tags_sets.get('TAG3', set())
condition_expression = condition_expression.replace('and', '&')
condition_expression = condition_expression.replace('or', '|')
# remove all quotes from the logical expression
condition_expression = condition_expression.replace('\'', '')
condition_expression = condition_expression.replace('\"', '')
condition_expression = re.sub("((\w|[-:\+])+)", rf"tags_sets.get('\1', set())", condition_expression)
exec_statement = "cond_expr_result = " + condition_expression
# this part executes the generated Python statement, and thus gets the list of matched objects
# from the tags_set content
exec_result = dict()
# execute our statement, exposing only the 'tags_set' dict. The result will be get on the exec_result dict
exec(exec_statement, {'tags_sets': tags_sets}, exec_result)
if exec_result.get('cond_expr_result'):
print(f"{len(exec_result.get('cond_expr_result'))} found")
return len(exec_result.get('cond_expr_result'))
return 0Part 3 : add it to our previous code so that we can use both matching methods for a given condition string and compare execution time
while True:
try:
condition_expression = input("DAG expression : ")
if condition_expression == "exit" or condition_expression == "":
break
print("Start search with iterative lookup")
start_find_iterative = datetime.datetime.now()
find_with_list_iteration(condition_expression)
end_find_iterative = datetime.datetime.now()
print(f"OK Took {end_find_iterative - start_find_iterative}")
print("Start search with sets operations")
start_find_sets = datetime.datetime.now()
find_with_sets(condition_expression)
end_find_sets = datetime.datetime.now()
print(f"OK Tool {end_find_sets - start_find_sets}")
except Exception as e:
print(e)
passExample of results with our examples random objects :
>>> DAG expression : 'TAG-1' and ('TAG-2' or 'TAG-3')
Start search with iterative lookup
Python statement is : cond_expr_result = 'TAG-1' in obj.tag and ('TAG-2' in obj.tag or 'TAG-3' in obj.tag)
41464 found
OK Took 0:00:04.515101
Start search with sets operations
Python statement is : cond_expr_result = tags_sets.get('TAG-1', set()) & (tags_sets.get('TAG-2', set()) | tags_sets.get('TAG-3', set()))
41464 found
OK Took 0:00:00.016188We can hopefully see that both methods are matching the exact same number of member objects, but we can also see how fast is the match using sets operations rather than through list iteration…
Test it “at scale” by generating DAG condition strings randomly
In order to compare how this improved matching logic would be profitable in a real use-case (at scale), let’s create a function able to create random DAG condition strings.
def gen_random_dag_string():
operators = {0: "and", 1: "or"}
max_groups = 3
max_tags_per_group = 3
condition = ""
for i in (last := range(random.randint(1, max_groups))):
condition += "("
for j in (last2 := range(random.randint(1, max_tags_per_group))):
condition += f"'{tag_list[random.randint(0, len(tag_list)-1)]}' "
condition += operators[random.randint(0, len(operators)-1)] + " " if j < last2[-1] else ""
condition += ")"
condition += " " + operators[random.randint(0, len(operators)-1)] + " " if i < last[-1] else ""
return conditionThis function is able to generate random conditions, using the tags from the tag_list.
Examples :
>>> print(gen_random_dag_string())
('TAG-0' and 'TAG-4' and 'TAG-5' ) or ('TAG-2' and 'TAG-4' )
>>> print(gen_random_dag_string())
('TAG-4' or 'TAG-0' and 'TAG-0' ) and ('TAG-0' or 'TAG-1' ) and ('TAG-5' )
>>> print(gen_random_dag_string())
('TAG-4' ) or ('TAG-0' and 'TAG-2' or 'TAG-1' ) or ('TAG-2' and 'TAG-3' )
>>> print(gen_random_dag_string())
('TAG-3' and 'TAG-5' or 'TAG-4' )
>>> print(gen_random_dag_string())
('TAG-3' ) and ('TAG-1' and 'TAG-4' )
>>> print(gen_random_dag_string())
('TAG-5' or 'TAG-1' and 'TAG-5' )Now let’s change a bit our code so that if we enter an integer value instead of a condition string, this amount of random conditions will be generated and evaluated among our 200k objects with both matching methods.
The time necessary to match the objects with both methods will be displayed, as well as the total number of objects (cumulating the match results length for each random condition string) so that we can make sure that both methods find exactly the same results.
while True:
try:
condition_expression = input("DAG expression : ")
if condition_expression == "exit" or condition_expression == "":
break
if condition_expression.isdigit():
nb_random_conditions = int(condition_expression)
print(f"Generating {nb_random_conditions} random DAG conditions...")
random_conditions = [gen_random_dag_string() for _ in range(int(nb_random_conditions))]
# Start using the iterative matching method
print(f"Resolving DAG members on {nb_random_conditions} DAGs with iterative method...")
start_find_iterative = datetime.datetime.now()
matched_total = 0
for random_cond in random_conditions:
matched_total += find_with_list_iteration(random_cond, print_count=False if nb_random_conditions > 10 else True)
end_find_iterative = datetime.datetime.now()
print(f"OK Took {end_find_iterative - start_find_iterative}")
print(f"Total : {matched_total} objects matched\n")
# Start using the sets operations method
print(f"Resolving DAG members on {nb_random_conditions} DAGs with sets...")
start_find_sets = datetime.datetime.now()
matched_total = 0
for random_cond in random_conditions:
matched_total += find_with_sets(random_cond, print_count=False if nb_random_conditions > 10 else True)
end_find_sets = datetime.datetime.now()
print(f"OK Took {end_find_sets - start_find_sets}")
print(f"Total : {matched_total} objects matched\n")Let’s test with some “small” values :
Matching among 20 random DAG condition strings :
>>> DAG expression : 20
Generating 20 random DAG conditions...
Resolving DAG members on 20 DAGs with iterative method...
OK Took 0:01:48.134561
Total : 1408129 objects matched
Resolving DAG members on 20 DAGs with sets...
OK Took 0:00:00.349032
Total : 1408129 objects matchedFor 200k objects match over 20 DAGs, 1:48 is needed for the iterative method while less than half a second is necessary for the sets operations method.
Find below some tests results with different amounts of DAG to be resolved :
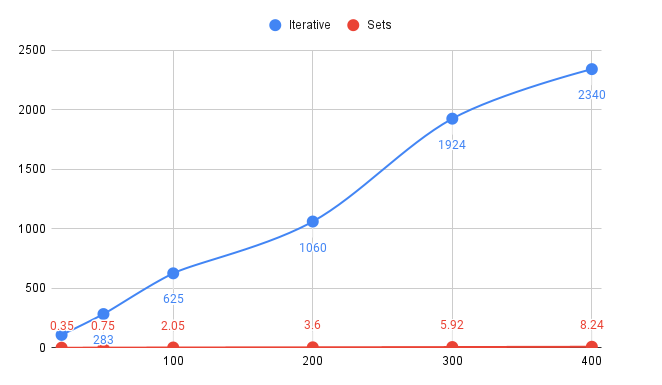
(Tests performed for 20 / 50 / 100 / 200 / 300 / 400 DAG conditions strings matches among 200k random objects).
Values are in seconds.
The full code used in this blog post and for my tests is available here : https://github.com/AnthoBalitrand/BLOG-palo-dag-resolving-methods
I hope that this will be useful, even to Palo Alto, to improve their matching logic and the time taken by commits on devices using a lot of objects and DAGs. The time needed to compile policies actually tends to make me think that they use an iterative method.
Moreover, not only it demonstrates how to improve the processing time for this specific use-case, but also that, when playing with significant amount of data, it is really important to understand the underlying logic that your different processings will use and the way you store your data, as it can amazingly impact the time and resource usage.