

In this (first) article, I will try to explain how Python track objects and reclaims memory space through its famous garbage collector. We’ll also learn (or review) some interesting stuff about Python variables and what they really are 🙂 .
Almost every Python developer knows that the interpreter is smart enough to manage memory by itself, which is one of the reasons which makes it handsome. However, most of them also confuses the garbage collector with the reference counting mechanism, which is way more active than the garbage collector in deleting unused (de-referenced) objects.
Please note that some principles have been highly simplified to make this article easily understandable 🙂
Reference counting : the main object tracker
As you probably already know, each object created in Python is assigned a unique ID, returned by the id() built-in function (with some specificities for immutable ones which can be interned, but that’s another story, we’ll talk about it on another article).
The variable name you assign to this new object is simply a “pointer name” to the memory address (at least part of it) of this new object.
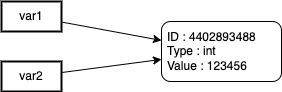
Let’s demonstrate it with a quick example :
>>> var1 = 123456
>>> id(var1)
4402893488
>>> var2 = var1
>>> id(var2)
4402893488In this code, an integer object containing 123456 is created, and the variable name var1 points to it.
We can display the id of the referenced string object by using the id() function on the variable name.
When creating the var2 variable and assigning var1 to it, Python creates a second reference to the same object (let’s say a “pointer” to the same memory address).
What is really behind the id() function output ?
Before going further, did you already ask yourself what is really the value returned by the id() function, and what it really represents ?
Does Python really generates a unique identifier for each and every new object created ?
First, we have to recall that Python is an interpreted language.
So each and every object created in your Python code is in fact an abstraction of a C structure, instantiated “on-the-flight” by the CPython interpreter (I will only talk about this one, which is the most widely used Python interpreter).
Depending of the object type you create on Python (integer, floating, char…) there’s a mapping to a C structure which will handle this object for you.
You can find detailed information about it here : https://docs.python.org/3/library/ctypes.html
What is important to understand, is that all of those different C structures representing the different Python objects types, all share the same “base” structure, which is the following :
typedef struct PyObject {
Py_ssize_t ob_refcnt; /* object reference count */
PyTypeObject* ob_type; /* object type */
} PyObject;The ob_refcnt variable (using a specific int type), contains the number of references, at any given time, to the instantiated PyObject.
The ob_type variable is another structure representing the Python object type.
So what is interesting, and what we have to remember for now, is that the id() Python function returns the memory address to the ob_refcnt variable of the CPython C object structure, which contains the number of references to this object.
Now that we have the address, how to get the value of this variable ?
As we just see, Python is continuously tracking the number of references to any object, thanks to the ob_refcnt variable of the underlying C structure.
How to get the value of this variable ? Using the ctypes module, which permits to manipulate C structures and functions.
>>> import ctypes
>>> ctypes.c_long.from_address(4402893488).value
2
>>> ctypes.c_long.from_address(id(var1)).value
2As we can see on the first output, the returned value is 2.
Updating the diagram we used before, here’s a different representation of what is happening under the curtain :
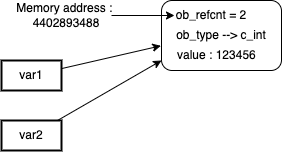
The second statement does the same by getting the object ID (= the memory address of its reference counter variable) using the id() function on var1.
But why is it not incrementing the refcount of the object then ?
In fact, it does, during the time the id(var1) function is executed.
Then this function returns the object ID “pointed” by var1 (4402893488), and puts it as an argument to the from_address() function. At this time, the reference created by the id() function does not exists anymore.
Now let’s delete var1, and see what happens to the refcount value of the object :
>>> del(var1)
>>> ctypes.c_long.from_address(4402893488).value
1By deleting var1, we did not delete the object, but just one of the references to this object. There’s still one reference to it, which is var2.
Now let’s delete var2 and see what happens if we try to display the ob_refcnt of the object, which is now deallocated (not pointed by any variable name) :
>>> del(var2)
>>> ctypes.c_long.from_address(4402893488).value
4459522800We can see that here, Python returns some random value which does not represents a refcount.
We are in fact getting the value of what is now stored at the memory address 4402893488, which is not occupied anymore by the underlying C structure (try it using a memory address not allocated to the CPython interpreter and you’ll get a nice segmentation fault 🙂 ).
It means that as soon as we deleted the remaining reference to the object ID 4402893488 (and thus decreased the refcount for this object to 0), it has been deleted by Python.
Thus, refcount = 0 means that the object disappears ?
Yes, and we can see it very clearly by creating a class, let’s say “Person”, which would be used to instantiate objects which would just contain 2 variables : firstname and lastname.
Note that each Python class has an __init__() method which is used to instantiate objects from this class.
But each class can also have a __del__() method, which will be called when the object deletion will be requested by Python (as you might guess, when the refcount for this object will reach 0).
Let’s create this class :
class Person:
def __init__(self, firstname, lastname):
self.firstname = firstname
self.lastname = lastname
print(f"Instanciated {self.firstname} {self.lastname}. ID = {id(self)}")
def __del__(self):
print(f"Deleting {self.firstname} {self.lastname}. ID = {id(self)}")And let’s create a first person :
>>> person1 = Person('john', 'smith')
Instanciated john smith. ID = 4459457264
>>> ctypes.c_long.from_address(4459457264).value
1We can see our only reference to the object ID 4459457264, which is from variable name “person1”.
Let’s create again a second variable, “person2”, pointing to the same object :
Of course, we have then 2 references to the same object. The refcount value for object ID 4459457264 is now 2.
>>> person2 = person1
>>> ctypes.c_long.from_address(4459457264).value
2Using again the same kind of diagrams as before, here’s what we have :

What happens if we delete person1 ?
>>> del(person1)
>>> ctypes.c_long.from_address(4459457264).value
1After deleting the “person1” variable, nothing happens. “person2” is still referencing object ID 4459457264, which maintains this object “alive”.
Now, what happens if we delete this only remaining reference to this object ?
>>> del(person2)
Deleting john smith. ID = 4459456304As soon as this last reference has been deleted, the refcount value for object ID 4459456304 has reached 0, which caused the memory space used by this object to be reclaimed by CPython, thus deleting the underlying C PyObject structure.
Note that this action is immediate : as soon as the refcount value equals 0, the object is deleted.
But note also that this is not done by the Python garbage collector :
Let’s try to disable the Python garbage collector (you can do that by importing the gc module and calling the gc.disable() function) :
>>> import gc
>>> gc.disable()
>>> gc.isenabled()
False
>>>
>>> person3 = Person("mac", "gyver")
Instanciated mac gyver. ID = 4458479568
>>> person4 = person3
>>> ctypes.c_long.from_address(4458479568).value
2
>>> del(person3)
>>> ctypes.c_long.from_address(4458479568).value
1
>>> del(person4)
Deleting mac gyver. ID = 4458479568Even with Python garbage collector disabled, objects for which the refcount value reaches 0 are always deleted.
But then, what does the Python garbage collector really do ???
Garbage collector : circular references
What we commonly call the “Garbage Collector” intervenes only on a specific scenario : circular references.
What is it ?
Let’s change a bit our Person class, so that we can link persons together. Let’s say we can add a brother_or_sister argument.
class Person:
def __init__(self, firstname, lastname):
self.firstname = firstname
self.lastname = lastname
self.brother_or_sister = None
print(f"Instanciated {self.firstname} {self.lastname}. ID = {id(self)}")
def __del__(self):
print(f"Deleting {self.firstname} {self.lastname}. ID = {id(self)}")Now let’s create two persons, and let’s make them brother and sister :
>>> s_jobs = Person('steve', 'jobs')
Instanciated steve jobs. ID = 4551724048
>>> m_simpson = Person('mona', 'simpson')
Instanciated mona simpson. ID = 4552865632
>>>
>>> s_jobs.brother_or_sister = m_simpson
>>> m_simpson.brother_or_sister = s_jobsAs you might guess, each of both created objects has 2 references :
– 1 from the pointing variable (ie : s_jobs points to object ID 4551724048)
– 1 from the other object’s “brother_or_sister” variable (ie : m_simpson.brother_or_sister also points to object ID 4551724048)
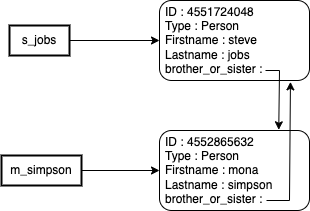
Let’s verify it :
>>> s_jobs_id = id(s_jobs)
>>> m_simpson_id = id(m_simpson)
>>>
>>> ctypes.c_long.from_address(s_jobs_id).value
2
>>> ctypes.c_long.from_address(m_simpson_id).value
2This interdependency means that deleting the two variables pointing to our objects (s_jobs and m_simpson) will still leave 1 reference existing for each object. This also means that it will avoid the reference counting tracker to immediately delete those objects :
>>> del(s_jobs)
>>> del(m_simpson)
>>>ctypes.c_long.from_address(s_jobs_id).value
1
>>> ctypes.c_long.from_address(m_simpson_id).value
1Here’s the representation at this point :
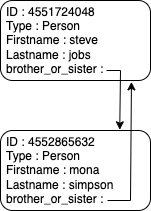
Both instances of the Person class are not referenced by a used variable anymore, but they are still inter-dependent one from each other.
And this is in this kind of situations where the garbage collector will intervene :
it is in charge of cleaning objects having inter-dependencies.
I will not detail here what is the underlying functioning of the garbage collector, which is quite complex.
You can find interesting information about it following this link : https://devguide.python.org/internals/garbage-collector/
However, what could be interesting to see, to end this blog post, is : does the garbage collector, as the reference count, is able to delete unreferenced objects immediately ?
And the answer to this question is : no, except if you ask for it explicitly.
The garbage collector is executed after a certain amount of allocations / deallocations of objects.
Allocating an object is, as you might guess, instantiating a new variable (and thus creating a new referenced object, or pointing to an existing one, ie : using var1 = var2 as we did at the beginning of this article), while deallocating an object is deleting this variable (and thus removing a reference to the object).
How to know at which interval the garbage collector is executed ?
To display the configured thresholds, you can use the following commands :
>>> import gc
>>> gc.get_threshold()
(700, 10, 10)The values displayed here are the default thresholds (I would recommend you not to modify it).
What does they mean ?
First, let’s talk about generations : there are 3 generations, on which objects are classed by the garbage collector.
Because of the functioning of the garbage collector, and because of the different levels of inter-dependencies between unallocated objects, objects might be deleted after only 1 garbage collector run (marked as unreachable), which are generation 0. Others would be marked as “tentatively unreachable” and would need another run to be cleaned (generation 1).
Objects still not cleaned at this point will be moved to the generation 2 container.
The different thresholds displayed by the get_threshold() means the following :
– Generation 0 (700) : as soon as the number of allocations minus deallocations is above this value, the garbage collector is started for generation 0
– Generation 1 (10) : as soon as there has been 10 collections for generation 0, start collection for generation 1
– Generation 2 (10) : as soon as there has been 10 collections for generation 1, start collection for generation 2
Let’s run it manually
Returning to our last example, we can try to run the garbage collector manually, and see if it will delete the deallocated (but still interdependant) Person objects :
>>> gc.collect()
Deleting steve jobs. ID = 4551724048
Deleting mona simpson. ID = 4552865632
2Not waiting for the thresholds to be reached, here we explicitly asked the garbage collector to be executed, using the gc.collect() function.
As we are in a situation with a simple one-level interdependency, our test objects are deleted immediately (placed into the generation 0 container).
The number “2” displayed by the gc.collect() function represents the number of objects which have been collected (deleted) by the garbage collector.
And we can confirm that this is our 2 “Person” instance objects which have been deleted, as their __del__() method has been called at the time of deletion, displaying their firstname, lastname variables, and their ID value (memory address of their ob_refcnt variable).
I hope that this first article was informative and interesting. Feel free to contact me if you have any comments, I will be happy to answer !
Find below some interesting links about the topic treated in this article :
https://devguide.python.org/internals/garbage-collector/
https://stackoverflow.com/questions/64561488/pythons-gc-get-objects-from-get-count
https://github.com/python/cpython
https://rushter.com/blog/python-garbage-collector/
https://www.honeybadger.io/blog/memory-management-in-python/
https://docs.python.org/3/library/ctypes.html
https://stackoverflow.com/questions/449560/how-do-i-determine-the-size-of-an-object-in-python